

In the last post, I explored what a flow was, brushed over it's purpose, their value where they can be found in the platform and finished with a brief exploration of Workflow Studio Home. This post will dig deeper into the anatomy of a Flow, including Triggers, Actions and the Flow execution process.
Reminder..
A Flow is a repeatable, idempotent sequence of actions which runs each time a condition is met to automate application or process business logic.
This could be to generate approvals for the commencement of work, creation of tasks, a unit of work assigned to a group or user and notifications to keep users informed of platform events.
A word on process..
Before digging into development, much like any other endeavour, a discovery of the existing process to be automated is a key aspect of design before development should begin.
This discovery should cover the entire end-to-end process and result in documentation of the process. This can then be collaborated on and ratified by management, business stakeholders and colleagues to ensure all aspects of the process intended for automation have been considered and fed into the design before development begins.
A very useful site for diagramming process can be found here:
Flow Anatomy
Flows have the following:
- Flow Properties
- A Trigger
- A sequence of actions
- Flow Logic (optional)
- Flow Data
Each of which will be described below.
Flow Properties
A Flow's properties is where general information is defined, such as it's name, a description detailing it's purpose, it's scope, protection state (read-only), what context the Flow will run under, (system user or the user who initiates the session), the roles it should execute with and finally Flow priority.

Trigger, Actions, Flow Logic and Flow Data
Once the properties for a Flow have been defined and saved, a new tab will open in Workflow Studio displaying the created flow, which we'll walk through.
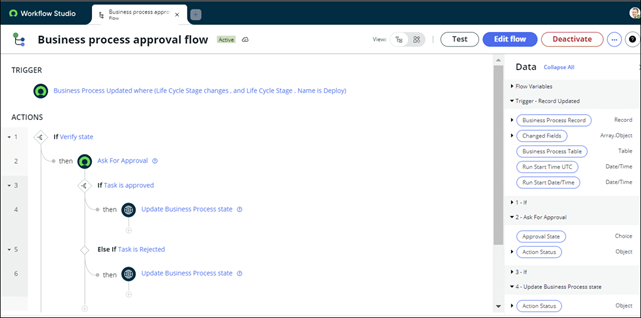
- Trigger - This is WHEN a flow should execute.
- Actions - This is WHAT a flow should execute.
- Flow Logic - This is where conditional or repeatable actions can be defined, using statements such as For Each, If or Do.
- Data - On the right-hand side is the Data panel. This is where Flows store data gathered or generated as variables. Each variable has it's own pill which can be dragged to an action input or output field.
How is a Flow processed?
When a Flow is triggered, flow processing occurs in this order and has the following characteristics:
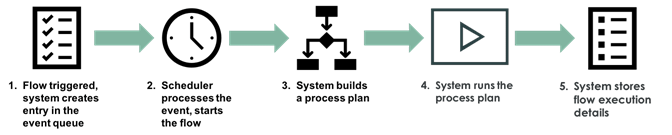
- Each time a Flow's trigger condition is met, an event entry is created by Flow Designer. The system processes triggers after database operations and typically synchronous business rules and workflows execute before a triggered flow.
- Each event entry contains references to the Flow to start and the triggering record or the execution time. These events are processed using the standard event processing by the system scheduler, which periodically works through the items in the event queue in the order they were added.
- When the event is pulled from the queue, a process plan is built by Flow designer to run the Flow. This process plan contains all the necessary information to execute a Flow and uses a just-in-time compilation scheme to ensure the latest version of the Flow will be executed. A cached copy of the flow is used if no changes have been detected following the first run.
- Flow Designer runs the newly built or cached process plan.
- Once the Flow has finished executing the process plan, the execution detail is stored in a Flow context record with the following attributes:
- Flow outcome state
- Flow runtime duration
- Flow log messages
- Flow configuration and runtime values.
- In addition, each Flow execution will have an outcome state:
- Complete: The flow completed successfully.
- In Progress: The flow is running.
- Waiting: The Flow is waiting for another event to occur.
- Cancelled: The Flow was cancelled by a user.
- Error: The Flow encountered and error and stopped running.
Flow error Handling
Each Flow has an Error handler which can be configured to log output values, send notifications and run corrective subflows when an error is encountered.
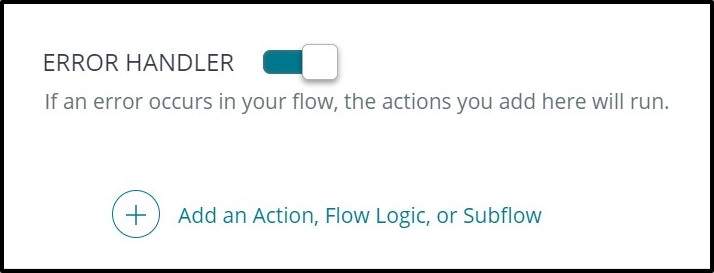
This is very useful for debugging flows and with a view to understanding the cause of errors in your flows.
In the next post, we'll go over Trigger and action definition and take a look at Flow execution details.
Thanks for reading.